Ernie 4.5 VL MoE
This model was released on 2025-06-30 and added to Hugging Face Transformers on TBD.




Ernie 4.5 VL MoE
Section titled “Ernie 4.5 VL MoE”Overview
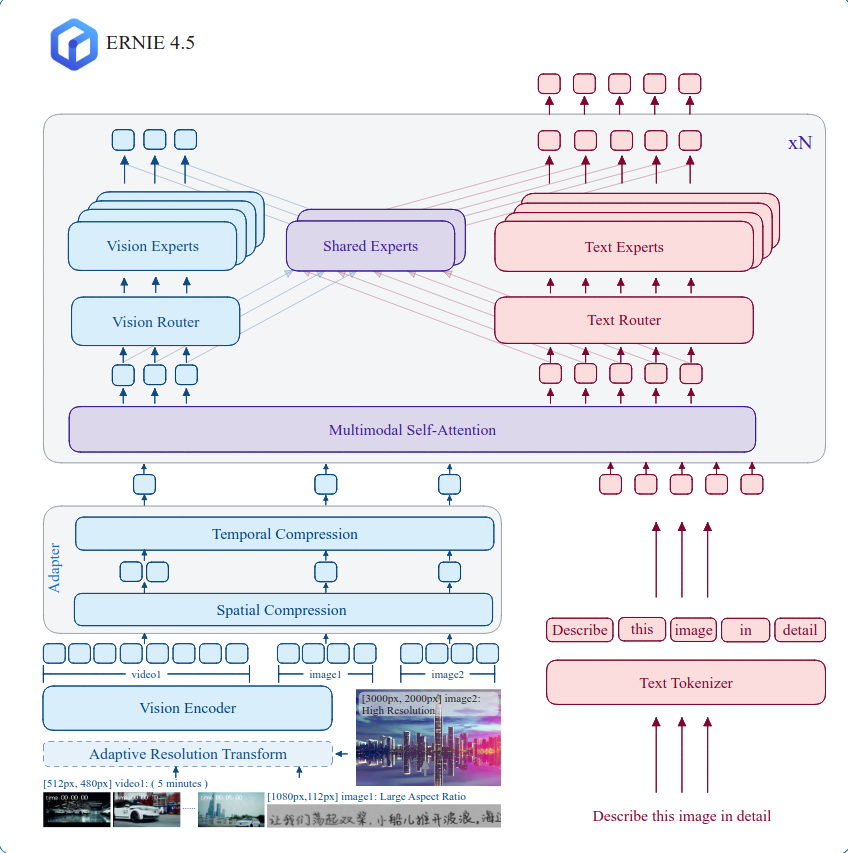
Section titled “Overview”The Ernie 4.5 VL MoE model was released in the Ernie 4.5 Model Family release by baidu. This family of models contains multiple different architectures and model sizes. The Vision-Language series in specific is composed of a novel multimodal heterogeneous structure, sharing paremeters across modalities and dedicating parameters to specific modalities. This becomes especially apparent in the Mixture of Expert (MoE) which is composed of
- Dedicated Text Experts
- Dedicated Vision Experts
- Shared Experts
This architecture has the advantage to enhance multimodal understanding without compromising, and even improving, performance on text-related tasks. An more detailed breakdown is given in the Technical Report.
Other models from the family can be found at Ernie 4.5 and at Ernie 4.5 MoE.
The example below demonstrates how to generate text based on an image with Pipeline or the AutoModel class.
from transformers import pipeline
pipe = pipeline( task="image-text-to-text", model="baidu/ERNIE-4.5-VL-28B-A3B-PT", device_map="auto", revision="refs/pr/10",)message = [ { "role": "user", "content": [ {"type": "text", "text": "What kind of dog is this?"}, { "type": "image", "url": "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg", }, ], }]print(pipe(text=message, max_new_tokens=20, return_full_text=False))from transformers import AutoModelForImageTextToText, AutoProcessor
model = AutoModelForImageTextToText.from_pretrained( "baidu/ERNIE-4.5-VL-28B-A3B-PT", dtype="auto", device_map="auto", # Use tp_plan="auto" instead to enable Tensor Parallelism! revision="refs/pr/10",)processor = AutoProcessor.from_pretrained( "baidu/ERNIE-4.5-VL-28B-A3B-PT", # use_fast=False, # closer to the original implementation for less speed revision="refs/pr/10",)message = [ { "role": "user", "content": [ {"type": "text", "text": "What kind of dog is this?"}, { "type": "image", "url": "https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/pipeline-cat-chonk.jpeg", }, ], }]
inputs = processor.apply_chat_template( message, add_generation_prompt=True, tokenize=True, return_dict=True, return_tensors="pt").to(model.device)
generated_ids = model.generate(**inputs, max_new_tokens=128)generated_ids_trimmed = [ out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)]output_text = processor.batch_decode( generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False)print(output_text)Using Ernie 4.5 VL MoE with video input is similar to using it with image input. The model can process video data and generate text based on the content of the video.
from transformers import AutoModelForImageTextToText, AutoProcessor
model = AutoModelForImageTextToText.from_pretrained( "baidu/ERNIE-4.5-VL-28B-A3B-PT", dtype="auto", device_map="auto", # Use tp_plan="auto" instead to enable Tensor Parallelism! revision="refs/pr/10",)processor = AutoProcessor.from_pretrained("baidu/ERNIE-4.5-VL-28B-A3B-PT", revision="refs/pr/10")message = [ { "role": "user", "content": [ {"type": "text", "text": "Please describe what you can see during this video."}, { "type": "video", "url": "https://huggingface.co/datasets/raushan-testing-hf/videos-test/resolve/main/tiny_video.mp4", }, ], }]
inputs = processor.apply_chat_template( message, add_generation_prompt=True, tokenize=True, return_dict=True, return_tensors="pt").to(model.device)
generated_ids = model.generate(**inputs, max_new_tokens=128)generated_ids_trimmed = [ out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)]output_text = processor.batch_decode( generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False)print(output_text)Ernie4_5_VL_MoeConfig
Section titled “Ernie4_5_VL_MoeConfig”[[autodoc]] Ernie4_5_VL_MoeConfig
Ernie4_5_VL_MoeTextConfig
Section titled “Ernie4_5_VL_MoeTextConfig”[[autodoc]] Ernie4_5_VL_MoeTextConfig
Ernie4_5_VL_MoeVisionConfig
Section titled “Ernie4_5_VL_MoeVisionConfig”[[autodoc]] Ernie4_5_VL_MoeVisionConfig
Ernie4_5_VL_MoeImageProcessor
Section titled “Ernie4_5_VL_MoeImageProcessor”[[autodoc]] Ernie4_5_VL_MoeImageProcessor - preprocess
Ernie4_5_VL_MoeImageProcessorFast
Section titled “Ernie4_5_VL_MoeImageProcessorFast”[[autodoc]] Ernie4_5_VL_MoeImageProcessorFast - preprocess
Ernie4_5_VL_MoeVideoProcessor
Section titled “Ernie4_5_VL_MoeVideoProcessor”[[autodoc]] Ernie4_5_VL_MoeVideoProcessor - preprocess
Ernie4_5_VL_MoeProcessor
Section titled “Ernie4_5_VL_MoeProcessor”[[autodoc]] Ernie4_5_VL_MoeProcessor
Ernie4_5_VL_MoeTextModel
Section titled “Ernie4_5_VL_MoeTextModel”[[autodoc]] Ernie4_5_VL_MoeTextModel - forward
Ernie4_5_VL_MoeVisionTransformerPretrainedModel
Section titled “Ernie4_5_VL_MoeVisionTransformerPretrainedModel”[[autodoc]] Ernie4_5_VL_MoeVisionTransformerPretrainedModel - forward
Ernie4_5_VL_MoeVariableResolutionResamplerModel
Section titled “Ernie4_5_VL_MoeVariableResolutionResamplerModel”[[autodoc]] Ernie4_5_VL_MoeVariableResolutionResamplerModel - forward
Ernie4_5_VL_MoeModel
Section titled “Ernie4_5_VL_MoeModel”[[autodoc]] Ernie4_5_VL_MoeModel - forward
Ernie4_5_VL_MoeForConditionalGeneration
Section titled “Ernie4_5_VL_MoeForConditionalGeneration”[[autodoc]] Ernie4_5_VL_MoeForConditionalGeneration - forward