V-JEPA 2
This model was released on 2025-06-11 and added to Hugging Face Transformers on 2025-06-11.



V-JEPA 2
Section titled “V-JEPA 2”V-JEPA 2 (blog post) is a self-supervised approach to training video encoders developed by FAIR, Meta. Using internet-scale video data, V-JEPA 2 attains state-of-the-art performance on motion understanding and human action anticipation tasks. V-JEPA 2-AC is a latent action-conditioned world model post-trained from V-JEPA 2 (using a small amount of robot trajectory interaction data) that solves robot manipulation tasks without environment-specific data collection or task-specific training or calibration.
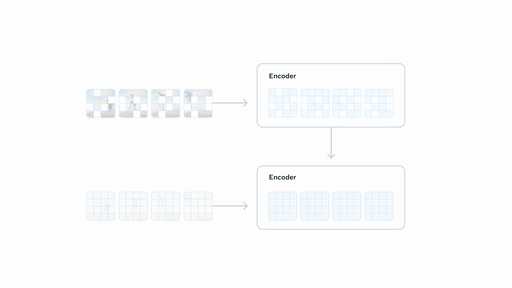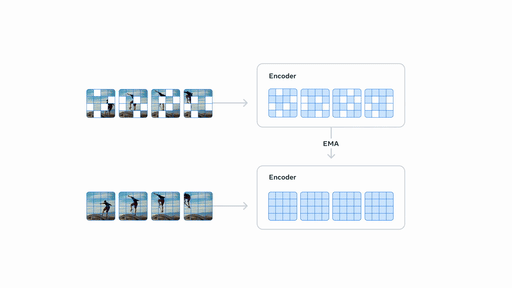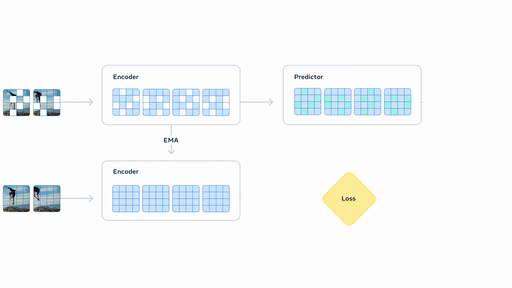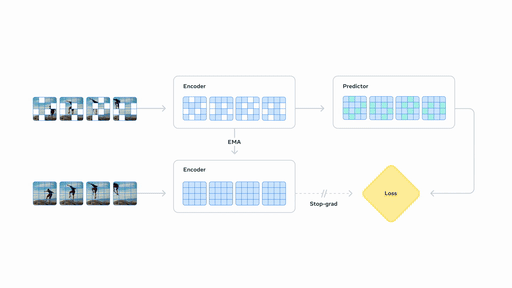
You can find all original V-JEPA2 checkpoints under the V-JEPA 2 collection.
This model was contributed by koustuvs, yonigozlan and qubvel. The original code can be found here.
Usage example
Section titled “Usage example”The snippet below shows how to load the V-JEPA 2 model for feature extraction using the AutoModel class.
import torchfrom torchcodec.decoders import VideoDecoderimport numpy as np
processor = AutoVideoProcessor.from_pretrained("facebook/vjepa2-vitl-fpc64-256")model = AutoModel.from_pretrained( "facebook/vjepa2-vitl-fpc64-256", dtype=torch.float16, device_map="auto", attn_implementation="sdpa")
video_url = "https://huggingface.co/datasets/nateraw/kinetics-mini/resolve/main/val/archery/-Qz25rXdMjE_000014_000024.mp4"
vr = VideoDecoder(video_url)frame_idx = np.arange(0, 64) # choosing some frames. here, you can define more complex sampling strategyvideo = vr.get_frames_at(indices=frame_idx).data # T x C x H x Wvideo = processor(video, return_tensors="pt").to(model.device)outputs = model(**video)
# V-JEPA 2 encoder outputs, same as calling `model.get_vision_features()`encoder_outputs = outputs.last_hidden_state
# V-JEPA 2 predictor outputspredictor_outputs = outputs.predictor_output.last_hidden_stateV-JEPA 2 can also be finetuned for video classification. In the following snippet, we show how use finetuned on Something-Something-V2 video classification model.
import torchimport numpy as np
from torchcodec.decoders import VideoDecoderfrom transformers import AutoVideoProcessor, AutoModelForVideoClassificationfrom accelerate import Accelerator
device = Accelerator().device
# Load model and video preprocessorhf_repo = "facebook/vjepa2-vitl-fpc16-256-ssv2"
model = AutoModelForVideoClassification.from_pretrained(hf_repo).to(device)processor = AutoVideoProcessor.from_pretrained(hf_repo)
# To load a video, sample the number of frames according to the model.video_url = "https://huggingface.co/datasets/nateraw/kinetics-mini/resolve/main/val/bowling/-WH-lxmGJVY_000005_000015.mp4"vr = VideoDecoder(video_url)frame_idx = np.arange(0, model.config.frames_per_clip, 8) # you can define more complex sampling strategyvideo = vr.get_frames_at(indices=frame_idx).data # frames x channels x height x width
# Preprocess and run inferenceinputs = processor(video, return_tensors="pt").to(model.device)with torch.no_grad(): outputs = model(**inputs)logits = outputs.logits
print("Top 5 predicted class names:")top5_indices = logits.topk(5).indices[0]top5_probs = torch.softmax(logits, dim=-1).topk(5).values[0]for idx, prob in zip(top5_indices, top5_probs): text_label = model.config.id2label[idx.item()] print(f" - {text_label}: {prob:.2f}")VJEPA2Config
Section titled “VJEPA2Config”[[autodoc]] VJEPA2Config
VJEPA2Model
Section titled “VJEPA2Model”[[autodoc]] VJEPA2Model - forward
VJEPA2ForVideoClassification
Section titled “VJEPA2ForVideoClassification”[[autodoc]] VJEPA2ForVideoClassification - forward
VJEPA2VideoProcessor
Section titled “VJEPA2VideoProcessor”[[autodoc]] VJEPA2VideoProcessor