VideoLLaMA3
This model was released on 2025-01-22 and added to Hugging Face Transformers on 2025-10-13.
VideoLLaMA3
Section titled “VideoLLaMA3”

Overview
Section titled “Overview”The VideoLLaMA3 model is a major update to VideoLLaMA2 from Alibaba DAMO Academy.
The abstract from the paper is as following:
In this paper, we propose VideoLLaMA 3, a more advanced multimodal foundation model for image and video understanding. The core design philosophy of VideoLLaMA3 is vision-centric. The meaning of “vision-centric” is two-fold: the vision-centric training paradigm and vision-centric framework design. The key insight of our vision-centric training paradigm is that high-quality image-text data is crucial for both image and video understanding. Instead of preparing massive video-text datasets, we focus on constructing large-scale, high-quality image-text datasets. VideoLLaMA3 has four training stages: 1) Vision Encoder Adaptation, which enables the vision encoder to accept images of variable resolutions as input; 2) Vision-Language Alignment, which jointly tunes the vision encoder, projector, and LLM with large-scale image-text data covering multiple types (including scene images, documents, and charts) as well as text-only data. 3) Multi-task Fine-tuning, which incorporates image-text SFT data for downstream tasks and video-text data to establish a foundation for video understanding. 4) Video-centric Fine-tuning, which further improves the model’s capability in video understanding. As for the framework design, to better capture fine-grained details in images, the pretrained vision encoder is adapted to encode images of varying sizes into vision tokens with corresponding numbers, rather than a fixed number of tokens. For video inputs, we reduce the number of vision tokens according to their similarity so that the representation of videos will be more precise and compact. Benefiting from vision-centric designs, VideoLLaMA3 achieves compelling performances in both image and video understanding benchmarks.
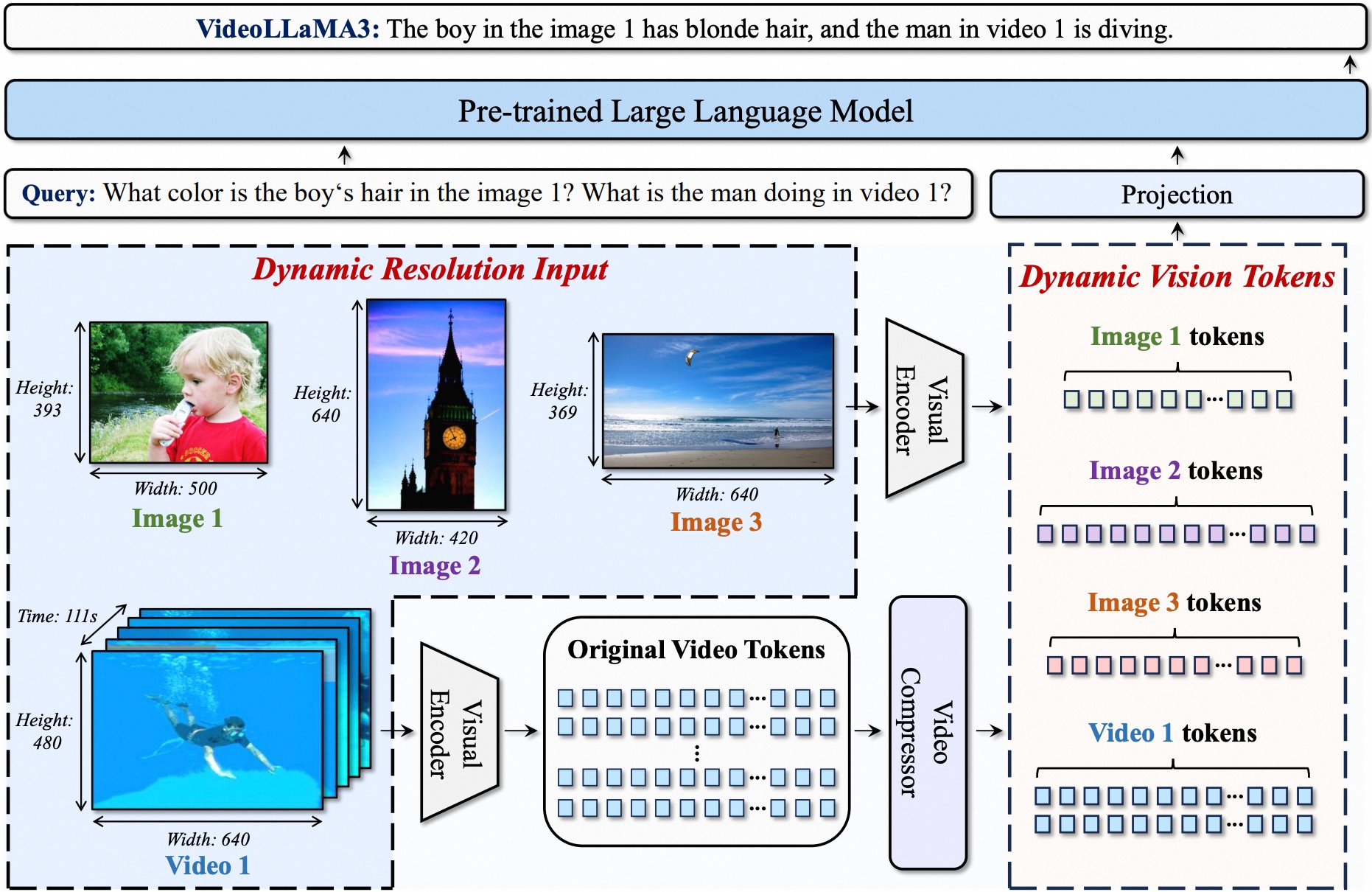
VideoLLaMA3 architecture. Taken from the technical report.
This model was contributed by lkhl.
Usage example
Section titled “Usage example”Single Media inference
Section titled “Single Media inference”The model can accept both images and videos as input. Here’s an example code for inference.
import torchfrom transformers import VideoLlama3ForConditionalGeneration, AutoTokenizer, AutoProcessor
# Load the model in half-precision on the available device(s)model = VideoLlama3ForConditionalGeneration.from_pretrained("lkhl/VideoLLaMA3-2B-Image-HF", device_map="auto")processor = AutoProcessor.from_pretrained("lkhl/VideoLLaMA3-2B-Image-HF")
conversation = [ { "role":"user", "content":[ {"type": "image", "image": "https://github.com/DAMO-NLP-SG/VideoLLaMA3/raw/refs/heads/main/assets/sora.png"}, {"type": "text", "text": "Describe this image."} ] }]
inputs = processor.apply_chat_template( conversation, add_generation_prompt=True, tokenize=True, return_dict=True, return_tensors="pt").to(model.device)
# Inference: Generation of the outputoutput_ids = model.generate(**inputs, max_new_tokens=128)generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(inputs.input_ids, output_ids)]output_text = processor.batch_decode(generated_ids, skip_special_tokens=True, clean_up_tokenization_spaces=True)print(output_text)
# Videoconversation = [ { "role": "user", "content": [ {"type": "video", "video": "https://github.com/DAMO-NLP-SG/VideoLLaMA3/raw/refs/heads/main/assets/cat_and_chicken.mp4"}, {"type": "text", "text": "What happened in the video?"}, ], }]
inputs = processor.apply_chat_template( conversation, fps=1, add_generation_prompt=True, tokenize=True, return_dict=True, return_tensors="pt").to(model.device)
# Inference: Generation of the outputoutput_ids = model.generate(**inputs, max_new_tokens=128)generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(inputs.input_ids, output_ids)]output_text = processor.batch_decode(generated_ids, skip_special_tokens=True, clean_up_tokenization_spaces=True)print(output_text)Batch Mixed Media Inference
Section titled “Batch Mixed Media Inference”The model can batch inputs composed of mixed samples of various types such as images, videos, and text. Here is an example.
# Imageconversation1 = [ { "role": "user", "content": [ {"type": "image", "image": "https://github.com/DAMO-NLP-SG/VideoLLaMA3/raw/refs/heads/main/assets/sora.png"}, {"type": "text", "text": "Describe this image."} ] }]
# Videoconversation2 = [ { "role": "user", "content": [ {"type": "video", "video": "https://github.com/DAMO-NLP-SG/VideoLLaMA3/raw/refs/heads/main/assets/cat_and_chicken.mp4"}, {"type": "text", "text": "What happened in the video?"}, ], }]
# Textconversation3 = [ { "role": "user", "content": "What color is a banana?" }]
conversations = [conversation1, conversation2, conversation3]# Preparation for batch inferenceinputs = processor.apply_chat_template( conversations, fps=1, add_generation_prompt=True, tokenize=True, padding=True, padding_side="left", return_dict=True, return_tensors="pt").to(model.device)
# Batch Inferenceoutput_ids = model.generate(**inputs, max_new_tokens=128)generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(inputs.input_ids, output_ids)]output_text = processor.batch_decode(generated_ids, skip_special_tokens=True, clean_up_tokenization_spaces=True)print(output_text)Flash-Attention 2 to speed up generation
Section titled “Flash-Attention 2 to speed up generation”First, make sure to install the latest version of Flash Attention 2:
pip install -U flash-attn --no-build-isolationAlso, you should have a hardware that is compatible with Flash-Attention 2. Read more about it in the official documentation of the flash attention repository. FlashAttention-2 can only be used when a model is loaded in torch.float16 or torch.bfloat16.
To load and run a model using Flash Attention-2, simply add attn_implementation="flash_attention_2" when loading the model as follows:
from transformers import VideoLlama3ForConditionalGeneration
model = VideoLlama3ForConditionalGeneration.from_pretrained( "lkhl/VideoLLaMA3-2B-Image-HF", dtype=torch.bfloat16, attn_implementation="flash_attention_2",)VideoLlama3Config
Section titled “VideoLlama3Config”[[autodoc]] VideoLlama3Config
VideoLlama3VisionConfig
Section titled “VideoLlama3VisionConfig”[[autodoc]] VideoLlama3VisionConfig
VideoLlama3ImageProcessor
Section titled “VideoLlama3ImageProcessor”[[autodoc]] VideoLlama3ImageProcessor - preprocess
VideoLlama3VideoProcessor
Section titled “VideoLlama3VideoProcessor”[[autodoc]] VideoLlama3VideoProcessor - preprocess
VideoLlama3ImageProcessorFast
Section titled “VideoLlama3ImageProcessorFast”[[autodoc]] VideoLlama3ImageProcessorFast - preprocess
VideoLlama3Processor
Section titled “VideoLlama3Processor”[[autodoc]] VideoLlama3Processor
VideoLlama3Model
Section titled “VideoLlama3Model”[[autodoc]] VideoLlama3Model - forward
VideoLlama3VisionModel
Section titled “VideoLlama3VisionModel”[[autodoc]] VideoLlama3VisionModel - forward
VideoLlama3ForConditionalGeneration
Section titled “VideoLlama3ForConditionalGeneration”[[autodoc]] VideoLlama3ForConditionalGeneration - forward