PaddleOCR-VL
This model was released on 2025-10-16 and added to Hugging Face Transformers on 2025-12-10.
PaddleOCR-VL
Section titled “PaddleOCR-VL”


Overview
Section titled “Overview”Huggingface Hub: PaddleOCR-VL | Github Repo: PaddleOCR
Official Website: Baidu AI Studio | arXiv: Technical Report
PaddleOCR-VL is a SOTA and resource-efficient model tailored for document parsing. Its core component is PaddleOCR-VL-0.9B, a compact yet powerful vision-language model (VLM) that integrates a NaViT-style dynamic resolution visual encoder with the ERNIE-4.5-0.3B language model to enable accurate element recognition. This innovative model efficiently supports 109 languages and excels in recognizing complex elements (e.g., text, tables, formulas, and charts), while maintaining minimal resource consumption. Through comprehensive evaluations on widely used public benchmarks and in-house benchmarks, PaddleOCR-VL achieves SOTA performance in both page-level document parsing and element-level recognition. It significantly outperforms existing solutions, exhibits strong competitiveness against top-tier VLMs, and delivers fast inference speeds. These strengths make it highly suitable for practical deployment in real-world scenarios.
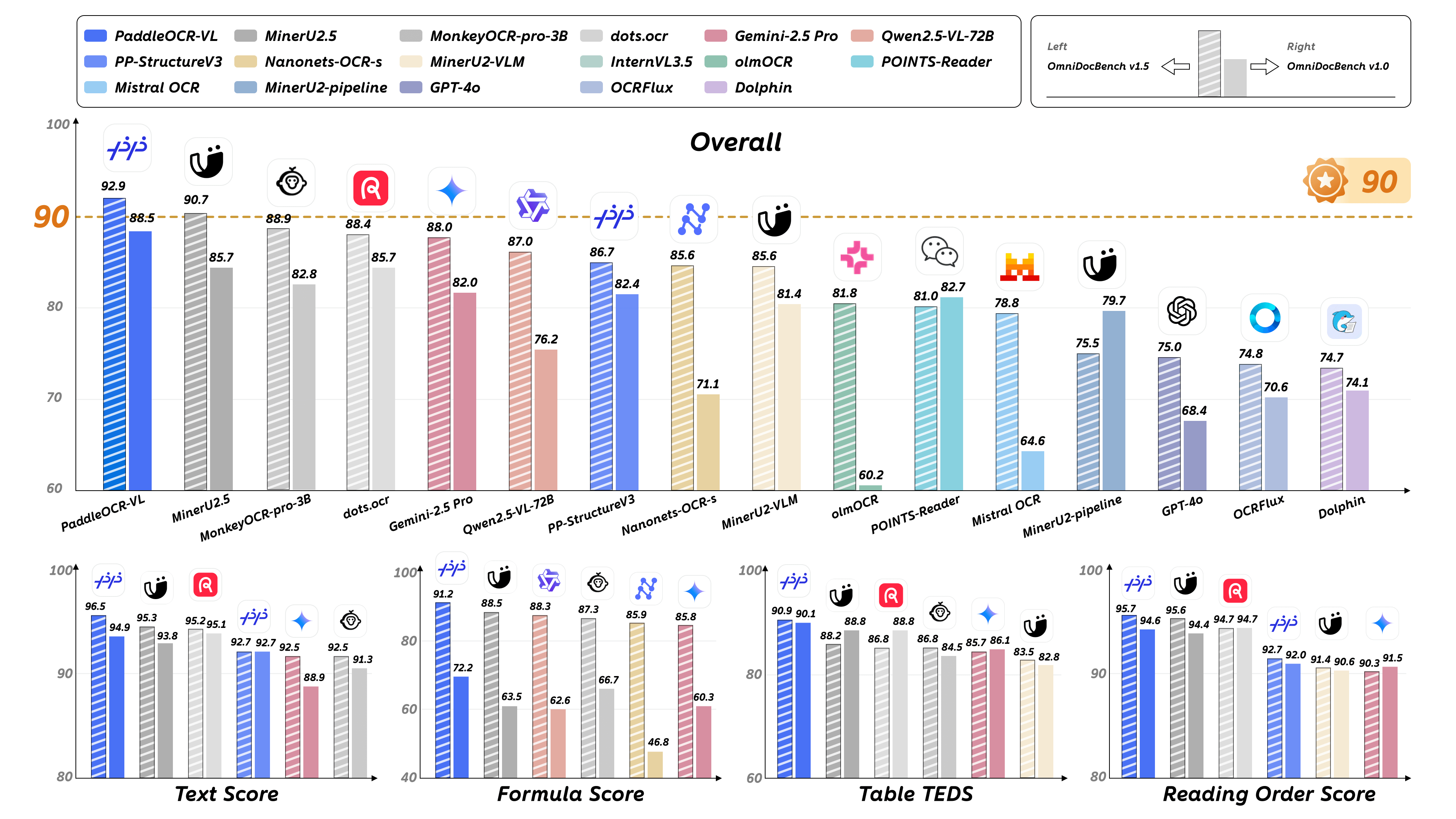
Core Features
Section titled “Core Features”-
Compact yet Powerful VLM Architecture: We present a novel vision-language model that is specifically designed for resource-efficient inference, achieving outstanding performance in element recognition. By integrating a NaViT-style dynamic high-resolution visual encoder with the lightweight ERNIE-4.5-0.3B language model, we significantly enhance the model’s recognition capabilities and decoding efficiency. This integration maintains high accuracy while reducing computational demands, making it well-suited for efficient and practical document processing applications.
-
SOTA Performance on Document Parsing: PaddleOCR-VL achieves state-of-the-art performance in both page-level document parsing and element-level recognition. It significantly outperforms existing pipeline-based solutions and exhibiting strong competitiveness against leading vision-language models (VLMs) in document parsing. Moreover, it excels in recognizing complex document elements, such as text, tables, formulas, and charts, making it suitable for a wide range of challenging content types, including handwritten text and historical documents. This makes it highly versatile and suitable for a wide range of document types and scenarios.
-
Multilingual Support: PaddleOCR-VL Supports 109 languages, covering major global languages, including but not limited to Chinese, English, Japanese, Latin, and Korean, as well as languages with different scripts and structures, such as Russian (Cyrillic script), Arabic, Hindi (Devanagari script), and Thai. This broad language coverage substantially enhances the applicability of our system to multilingual and globalized document processing scenarios.
Model Architecture
Section titled “Model Architecture”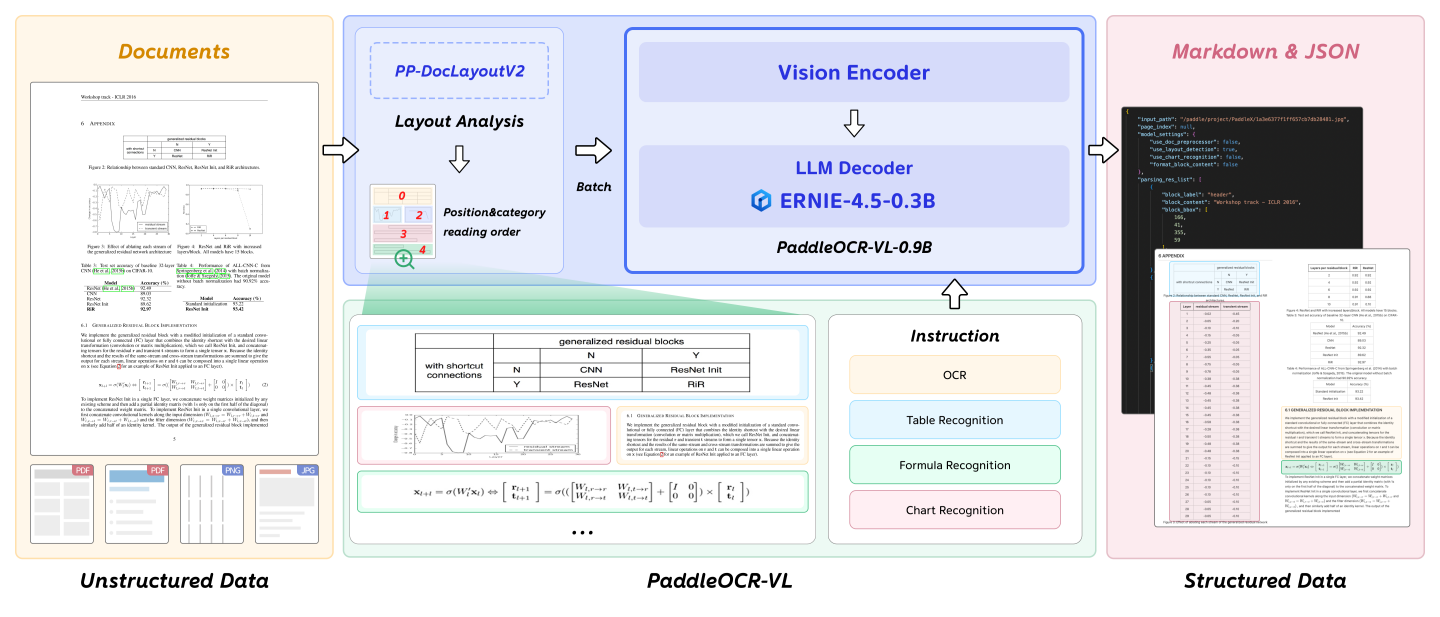
Usage tips
Section titled “Usage tips”We have four types of element-level recognition:
- Text recognition, indicated by the prompt
OCR:. - Formula recognition, indicated by the prompt
Formula Recognition:. - Table recognition, indicated by the prompt
Table Recognition:. - Chart recognition, indicated by the prompt
Chart Recognition:.
The following examples are all based on text recognition, with the prompt OCR:.
Single input inference
Section titled “Single input inference”The example below demonstrates how to generate text with PaddleOCRVL using Pipeline or the AutoModel.
from transformers import pipeline
pipe = pipeline("image-text-to-text", model="PaddlePaddle/PaddleOCR-VL", dtype="bfloat16")messages = [ { "role": "user", "content": [ {"type": "image", "url": "https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/ocr_demo2.jpg"}, {"type": "text", "text": "OCR:"}, ] }]result = pipe(text=messages)print(result[0]["generated_text"])from transformers import AutoProcessor, AutoModelForImageTextToText
model = AutoModelForImageTextToText.from_pretrained("PaddlePaddle/PaddleOCR-VL", dtype="bfloat16")processor = AutoProcessor.from_pretrained("PaddlePaddle/PaddleOCR-VL")messages = [ { "role": "user", "content": [ {"type": "image", "url": "https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/ocr_demo2.jpg"}, {"type": "text", "text": "OCR:"}, ] }]inputs = processor.apply_chat_template( messages, add_generation_prompt=True, tokenize=True, return_dict=True, return_tensors="pt",).to(model.device)
outputs = model.generate(**inputs, max_new_tokens=100)result = processor.decode(outputs[0][inputs["input_ids"].shape[-1]:-1])print(result)Batched inference
Section titled “Batched inference”PaddleOCRVL also supports batched inference. We advise users to use padding_side="left" when computing batched generation as it leads to more accurate results. Here is how you can do it with PaddleOCRVL using Pipeline or the AutoModel:
from transformers import pipeline
pipe = pipeline("image-text-to-text", model="PaddlePaddle/PaddleOCR-VL", dtype="bfloat16")messages = [ { "role": "user", "content": [ {"type": "image", "url": "https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/ocr_demo2.jpg"}, {"type": "text", "text": "OCR:"}, ] }]result = pipe(text=[messages, messages])print(result[0][0]["generated_text"])print(result[1][0]["generated_text"])from transformers import AutoProcessor, AutoModelForImageTextToText
model = AutoModelForImageTextToText.from_pretrained("PaddlePaddle/PaddleOCR-VL", dtype="bfloat16")processor = AutoProcessor.from_pretrained("PaddlePaddle/PaddleOCR-VL")messages = [ { "role": "user", "content": [ {"type": "image", "url": "https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/ocr_demo2.jpg"}, {"type": "text", "text": "OCR:"}, ] }]batch_messages = [messages, messages]inputs = processor.apply_chat_template( batch_messages, add_generation_prompt=True, tokenize=True, return_dict=True, return_tensors="pt", padding=True, padding_side='left',).to(model.device)
generated_ids = model.generate(**inputs, max_new_tokens=100)generated_ids_trimmed = [out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)]result = processor.batch_decode(generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False)print(result)Using Flash Attention 2
Section titled “Using Flash Attention 2”Flash Attention 2 is an even faster, optimized version of the previous optimization, please refer to the FlashAttention.
For example:
pip install flash-attn --no-build-isolationfrom transformers import AutoModelForImageTextToTextmodel = AutoModelForImageTextToText.from_pretrained("PaddlePaddle/PaddleOCR-VL", dtype="bfloat16", attn_implementation="flash_attention_2")PaddleOCRVLForConditionalGeneration
Section titled “PaddleOCRVLForConditionalGeneration”[[autodoc]] PaddleOCRVLForConditionalGeneration - forward
PaddleOCRVLConfig
Section titled “PaddleOCRVLConfig”[[autodoc]] PaddleOCRVLConfig
PaddleOCRVisionConfig
Section titled “PaddleOCRVisionConfig”[[autodoc]] PaddleOCRVisionConfig
PaddleOCRTextConfig
Section titled “PaddleOCRTextConfig”[[autodoc]] PaddleOCRTextConfig
PaddleOCRTextModel
Section titled “PaddleOCRTextModel”[[autodoc]] PaddleOCRTextModel
PaddleOCRVisionModel
Section titled “PaddleOCRVisionModel”[[autodoc]] PaddleOCRVisionModel
PaddleOCRVLImageProcessor
Section titled “PaddleOCRVLImageProcessor”[[autodoc]] PaddleOCRVLImageProcessor
PaddleOCRVLImageProcessorFast
Section titled “PaddleOCRVLImageProcessorFast”[[autodoc]] PaddleOCRVLImageProcessorFast
PaddleOCRVLModel
Section titled “PaddleOCRVLModel”[[autodoc]] PaddleOCRVLModel
PaddleOCRVLProcessor
Section titled “PaddleOCRVLProcessor”[[autodoc]] PaddleOCRVLProcessor
PaddleOCRVisionTransformer
Section titled “PaddleOCRVisionTransformer”[[autodoc]] PaddleOCRVisionTransformer