OmDet-Turbo
This model was released on 2024-03-11 and added to Hugging Face Transformers on 2024-09-25.
OmDet-Turbo
Section titled “OmDet-Turbo”
Overview
Section titled “Overview”The OmDet-Turbo model was proposed in Real-time Transformer-based Open-Vocabulary Detection with Efficient Fusion Head by Tiancheng Zhao, Peng Liu, Xuan He, Lu Zhang, Kyusong Lee. OmDet-Turbo incorporates components from RT-DETR and introduces a swift multimodal fusion module to achieve real-time open-vocabulary object detection capabilities while maintaining high accuracy. The base model achieves performance of up to 100.2 FPS and 53.4 AP on COCO zero-shot.
The abstract from the paper is the following:
End-to-end transformer-based detectors (DETRs) have shown exceptional performance in both closed-set and open-vocabulary object detection (OVD) tasks through the integration of language modalities. However, their demanding computational requirements have hindered their practical application in real-time object detection (OD) scenarios. In this paper, we scrutinize the limitations of two leading models in the OVDEval benchmark, OmDet and Grounding-DINO, and introduce OmDet-Turbo. This novel transformer-based real-time OVD model features an innovative Efficient Fusion Head (EFH) module designed to alleviate the bottlenecks observed in OmDet and Grounding-DINO. Notably, OmDet-Turbo-Base achieves a 100.2 frames per second (FPS) with TensorRT and language cache techniques applied. Notably, in zero-shot scenarios on COCO and LVIS datasets, OmDet-Turbo achieves performance levels nearly on par with current state-of-the-art supervised models. Furthermore, it establishes new state-of-the-art benchmarks on ODinW and OVDEval, boasting an AP of 30.1 and an NMS-AP of 26.86, respectively. The practicality of OmDet-Turbo in industrial applications is underscored by its exceptional performance on benchmark datasets and superior inference speed, positioning it as a compelling choice for real-time object detection tasks.
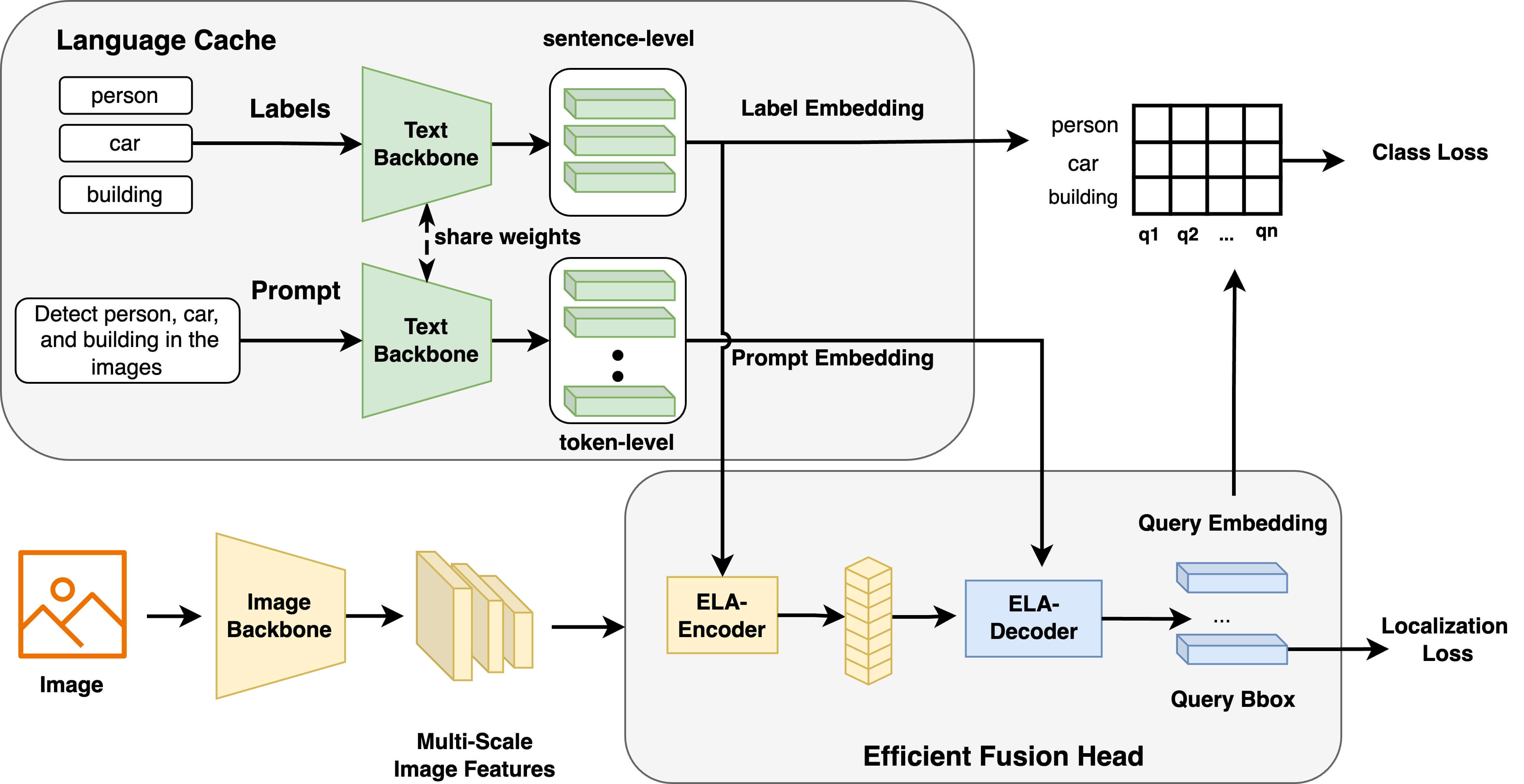
OmDet-Turbo architecture overview. Taken from the original paper.
This model was contributed by yonigozlan. The original code can be found here.
Usage tips
Section titled “Usage tips”One unique property of OmDet-Turbo compared to other zero-shot object detection models, such as Grounding DINO, is the decoupled classes and prompt embedding structure that allows caching of text embeddings. This means that the model needs both classes and task as inputs, where classes is a list of objects we want to detect and task is the grounded text used to guide open-vocabulary detection. This approach limits the scope of the open-vocabulary detection and makes the decoding process faster.
OmDetTurboProcessor is used to prepare the classes, task and image triplet. The task input is optional, and when not provided, it will default to "Detect [class1], [class2], [class3], ...". To process the results from the model, one can use post_process_grounded_object_detection from OmDetTurboProcessor. Notably, this function takes in the input classes, as unlike other zero-shot object detection models, the decoupling of classes and task embeddings means that no decoding of the predicted class embeddings is needed in the post-processing step, and the predicted classes can be matched to the inputted ones directly.
Usage example
Section titled “Usage example”Single image inference
Section titled “Single image inference”Here’s how to load the model and prepare the inputs to perform zero-shot object detection on a single image:
>>> import torch>>> import requests>>> from PIL import Image
>>> from transformers import AutoProcessor, OmDetTurboForObjectDetection
>>> processor = AutoProcessor.from_pretrained("omlab/omdet-turbo-swin-tiny-hf")>>> model = OmDetTurboForObjectDetection.from_pretrained("omlab/omdet-turbo-swin-tiny-hf")
>>> url = "http://images.cocodataset.org/val2017/000000039769.jpg">>> image = Image.open(requests.get(url, stream=True).raw)>>> text_labels = ["cat", "remote"]>>> inputs = processor(image, text=text_labels, return_tensors="pt")
>>> with torch.no_grad():... outputs = model(**inputs)
>>> # convert outputs (bounding boxes and class logits)>>> results = processor.post_process_grounded_object_detection(... outputs,... target_sizes=[(image.height, image.width)],... text_labels=text_labels,... threshold=0.3,... nms_threshold=0.3,... )>>> result = results[0]>>> boxes, scores, text_labels = result["boxes"], result["scores"], result["text_labels"]>>> for box, score, text_label in zip(boxes, scores, text_labels):... box = [round(i, 2) for i in box.tolist()]... print(f"Detected {text_label} with confidence {round(score.item(), 3)} at location {box}")Detected remote with confidence 0.768 at location [39.89, 70.35, 176.74, 118.04]Detected cat with confidence 0.72 at location [11.6, 54.19, 314.8, 473.95]Detected remote with confidence 0.563 at location [333.38, 75.77, 370.7, 187.03]Detected cat with confidence 0.552 at location [345.15, 23.95, 639.75, 371.67]Multi image inference
Section titled “Multi image inference”OmDet-Turbo can perform batched multi-image inference, with support for different text prompts and classes in the same batch:
>>> import torch>>> import requests>>> from io import BytesIO>>> from PIL import Image>>> from transformers import AutoProcessor, OmDetTurboForObjectDetection
>>> processor = AutoProcessor.from_pretrained("omlab/omdet-turbo-swin-tiny-hf")>>> model = OmDetTurboForObjectDetection.from_pretrained("omlab/omdet-turbo-swin-tiny-hf")
>>> url1 = "http://images.cocodataset.org/val2017/000000039769.jpg">>> image1 = Image.open(BytesIO(requests.get(url1).content)).convert("RGB")>>> text_labels1 = ["cat", "remote"]>>> task1 = "Detect {}.".format(", ".join(text_labels1))
>>> url2 = "http://images.cocodataset.org/train2017/000000257813.jpg">>> image2 = Image.open(BytesIO(requests.get(url2).content)).convert("RGB")>>> text_labels2 = ["boat"]>>> task2 = "Detect everything that looks like a boat."
>>> url3 = "https://cdn.britannica.com/61/93061-050-99147DCE/Statue-of-Liberty-Island-New-York-Bay.jpg">>> image3 = Image.open(BytesIO(requests.get(url3).content)).convert("RGB")>>> text_labels3 = ["statue", "trees"]>>> task3 = "Focus on the foreground, detect statue and trees."
>>> inputs = processor(... images=[image1, image2, image3],... text=[text_labels1, text_labels2, text_labels3],... task=[task1, task2, task3],... return_tensors="pt",... )
>>> with torch.no_grad():... outputs = model(**inputs)
>>> # convert outputs (bounding boxes and class logits)>>> results = processor.post_process_grounded_object_detection(... outputs,... text_labels=[text_labels1, text_labels2, text_labels3],... target_sizes=[(image.height, image.width) for image in [image1, image2, image3]],... threshold=0.2,... nms_threshold=0.3,... )
>>> for i, result in enumerate(results):... for score, text_label, box in zip(... result["scores"], result["text_labels"], result["boxes"]... ):... box = [round(i, 1) for i in box.tolist()]... print(... f"Detected {text_label} with confidence "... f"{round(score.item(), 2)} at location {box} in image {i}"... )Detected remote with confidence 0.77 at location [39.9, 70.4, 176.7, 118.0] in image 0Detected cat with confidence 0.72 at location [11.6, 54.2, 314.8, 474.0] in image 0Detected remote with confidence 0.56 at location [333.4, 75.8, 370.7, 187.0] in image 0Detected cat with confidence 0.55 at location [345.2, 24.0, 639.8, 371.7] in image 0Detected boat with confidence 0.32 at location [146.9, 219.8, 209.6, 250.7] in image 1Detected boat with confidence 0.3 at location [319.1, 223.2, 403.2, 238.4] in image 1Detected boat with confidence 0.27 at location [37.7, 220.3, 84.0, 235.9] in image 1Detected boat with confidence 0.22 at location [407.9, 207.0, 441.7, 220.2] in image 1Detected statue with confidence 0.73 at location [544.7, 210.2, 651.9, 502.8] in image 2Detected trees with confidence 0.25 at location [3.9, 584.3, 391.4, 785.6] in image 2Detected trees with confidence 0.25 at location [1.4, 621.2, 118.2, 787.8] in image 2Detected statue with confidence 0.2 at location [428.1, 205.5, 767.3, 759.5] in image 2OmDetTurboConfig
Section titled “OmDetTurboConfig”[[autodoc]] OmDetTurboConfig
OmDetTurboProcessor
Section titled “OmDetTurboProcessor”[[autodoc]] OmDetTurboProcessor - post_process_grounded_object_detection
OmDetTurboForObjectDetection
Section titled “OmDetTurboForObjectDetection”[[autodoc]] OmDetTurboForObjectDetection - forward