LayoutLMv3
This model was released on 2022-04-18 and added to Hugging Face Transformers on 2022-05-24.
LayoutLMv3
Section titled “LayoutLMv3”Overview
Section titled “Overview”The LayoutLMv3 model was proposed in LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking by Yupan Huang, Tengchao Lv, Lei Cui, Yutong Lu, Furu Wei. LayoutLMv3 simplifies LayoutLMv2 by using patch embeddings (as in ViT) instead of leveraging a CNN backbone, and pre-trains the model on 3 objectives: masked language modeling (MLM), masked image modeling (MIM) and word-patch alignment (WPA).
The abstract from the paper is the following:
Self-supervised pre-training techniques have achieved remarkable progress in Document AI. Most multimodal pre-trained models use a masked language modeling objective to learn bidirectional representations on the text modality, but they differ in pre-training objectives for the image modality. This discrepancy adds difficulty to multimodal representation learning. In this paper, we propose LayoutLMv3 to pre-train multimodal Transformers for Document AI with unified text and image masking. Additionally, LayoutLMv3 is pre-trained with a word-patch alignment objective to learn cross-modal alignment by predicting whether the corresponding image patch of a text word is masked. The simple unified architecture and training objectives make LayoutLMv3 a general-purpose pre-trained model for both text-centric and image-centric Document AI tasks. Experimental results show that LayoutLMv3 achieves state-of-the-art performance not only in text-centric tasks, including form understanding, receipt understanding, and document visual question answering, but also in image-centric tasks such as document image classification and document layout analysis.
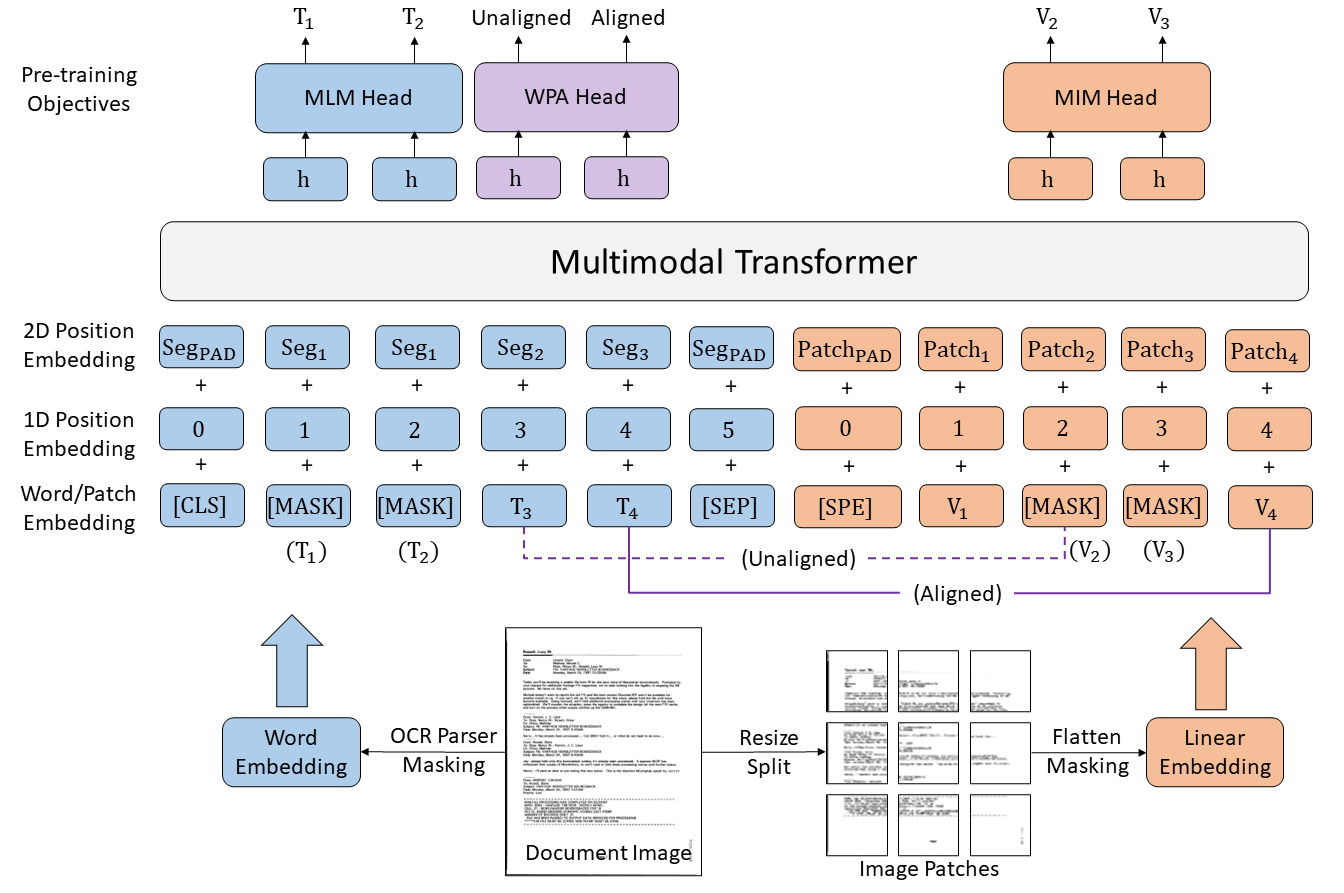
LayoutLMv3 architecture. Taken from the original paper.
This model was contributed by nielsr. The original code can be found here.
Usage tips
Section titled “Usage tips”- In terms of data processing, LayoutLMv3 is identical to its predecessor LayoutLMv2, except that:
- images need to be resized and normalized with channels in regular RGB format. LayoutLMv2 on the other hand normalizes the images internally and expects the channels in BGR format.
- text is tokenized using byte-pair encoding (BPE), as opposed to WordPiece.
Due to these differences in data preprocessing, one can use
LayoutLMv3Processorwhich internally combines aLayoutLMv3ImageProcessor(for the image modality) and aLayoutLMv3Tokenizer/LayoutLMv3TokenizerFast(for the text modality) to prepare all data for the model.
- Regarding usage of
LayoutLMv3Processor, we refer to the usage guide of its predecessor.
Resources
Section titled “Resources”A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with LayoutLMv3. If you’re interested in submitting a resource to be included here, please feel free to open a Pull Request and we’ll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
LayoutLMv3 is nearly identical to LayoutLMv2, so we’ve also included LayoutLMv2 resources you can adapt for LayoutLMv3 tasks. For these notebooks, take care to use LayoutLMv2Processor instead when preparing data for the model!
LayoutLMv2ForSequenceClassificationis supported by this notebook.- Text classification task guide
LayoutLMv3ForTokenClassificationis supported by this example script and notebook.- A notebook for how to perform inference with
LayoutLMv2ForTokenClassificationand a notebook for how to perform inference when no labels are available withLayoutLMv2ForTokenClassification. - A notebook for how to finetune
LayoutLMv2ForTokenClassificationwith the 🤗 Trainer. - Token classification task guide
LayoutLMv2ForQuestionAnsweringis supported by this notebook.- Question answering task guide
Document question answering
LayoutLMv3Config
Section titled “LayoutLMv3Config”[[autodoc]] LayoutLMv3Config
LayoutLMv3ImageProcessor
Section titled “LayoutLMv3ImageProcessor”[[autodoc]] LayoutLMv3ImageProcessor - preprocess
LayoutLMv3ImageProcessorFast
Section titled “LayoutLMv3ImageProcessorFast”[[autodoc]] LayoutLMv3ImageProcessorFast - preprocess
LayoutLMv3Tokenizer
Section titled “LayoutLMv3Tokenizer”[[autodoc]] LayoutLMv3Tokenizer - call - save_vocabulary
LayoutLMv3TokenizerFast
Section titled “LayoutLMv3TokenizerFast”[[autodoc]] LayoutLMv3TokenizerFast - call
LayoutLMv3Processor
Section titled “LayoutLMv3Processor”[[autodoc]] LayoutLMv3Processor - call
LayoutLMv3Model
Section titled “LayoutLMv3Model”[[autodoc]] LayoutLMv3Model - forward
LayoutLMv3ForSequenceClassification
Section titled “LayoutLMv3ForSequenceClassification”[[autodoc]] LayoutLMv3ForSequenceClassification - forward
LayoutLMv3ForTokenClassification
Section titled “LayoutLMv3ForTokenClassification”[[autodoc]] LayoutLMv3ForTokenClassification - forward
LayoutLMv3ForQuestionAnswering
Section titled “LayoutLMv3ForQuestionAnswering”[[autodoc]] LayoutLMv3ForQuestionAnswering - forward