Kyutai Speech-To-Text
This model was released on 2025-06-17 and added to Hugging Face Transformers on 2025-06-25.
Kyutai Speech-To-Text
Section titled “Kyutai Speech-To-Text”Overview
Section titled “Overview”Kyutai STT is a speech-to-text model architecture based on the Mimi codec, which encodes audio into discrete tokens in a streaming fashion, and a Moshi-like autoregressive decoder. Kyutai’s lab has released two model checkpoints:
- kyutai/stt-1b-en_fr: a 1B-parameter model capable of transcribing both English and French
- kyutai/stt-2.6b-en: a 2.6B-parameter model focused solely on English, optimized for maximum transcription accuracy
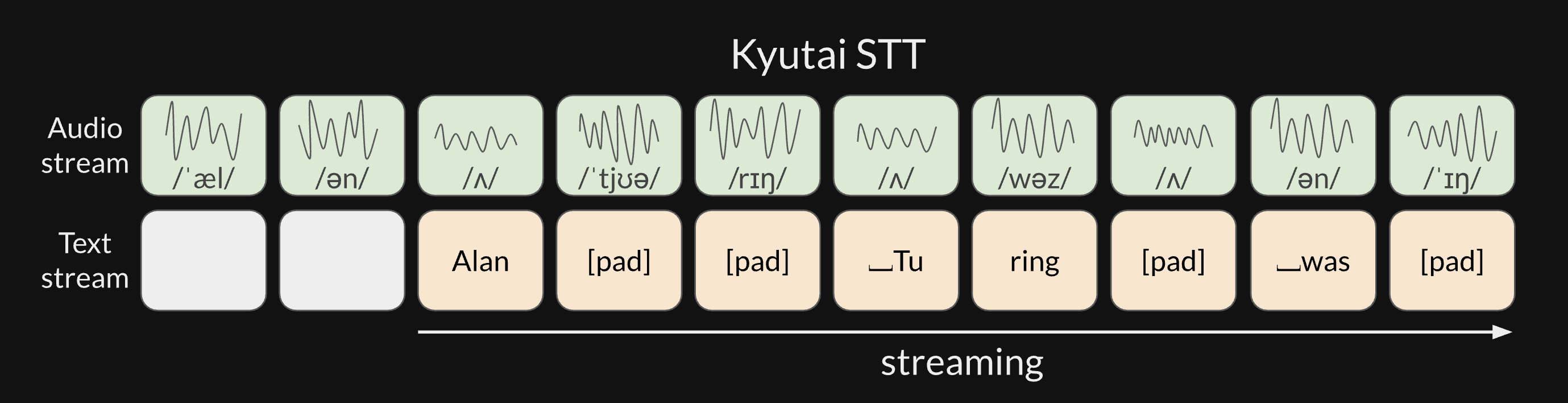
Usage Tips
Section titled “Usage Tips”Inference
Section titled “Inference”import torchfrom datasets import load_dataset, Audiofrom transformers import KyutaiSpeechToTextProcessor, KyutaiSpeechToTextForConditionalGenerationfrom accelerate import Accelerator
# 1. load the model and the processortorch_device = Accelerator().devicemodel_id = "kyutai/stt-2.6b-en-trfs"
processor = KyutaiSpeechToTextProcessor.from_pretrained(model_id)model = KyutaiSpeechToTextForConditionalGeneration.from_pretrained(model_id, device_map=torch_device, dtype="auto")
# 2. load audio samplesds = load_dataset( "hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")ds = ds.cast_column("audio", Audio(sampling_rate=24000))
# 3. prepare the model inputsinputs = processor( ds[0]["audio"]["array"],)inputs.to(model.device)
# 4. infer the modeloutput_tokens = model.generate(**inputs)
# 5. decode the generated tokensprint(processor.batch_decode(output_tokens, skip_special_tokens=True))Batched Inference
Section titled “Batched Inference”import torchfrom datasets import load_dataset, Audiofrom transformers import KyutaiSpeechToTextProcessor, KyutaiSpeechToTextForConditionalGenerationfrom accelerate import Accelerator
# 1. load the model and the processortorch_device = Accelerator().devicemodel_id = "kyutai/stt-2.6b-en-trfs"
processor = KyutaiSpeechToTextProcessor.from_pretrained(model_id)model = KyutaiSpeechToTextForConditionalGeneration.from_pretrained(model_id, device_map=torch_device, dtype="auto")
# 2. load audio samplesds = load_dataset( "hf-internal-testing/librispeech_asr_dummy", "clean", split="validation")ds = ds.cast_column("audio", Audio(sampling_rate=24000))
# 3. prepare the model inputsaudio_arrays = [ds[i]["audio"]["array"] for i in range(4)]inputs = processor(audio_arrays, return_tensors="pt", padding=True)inputs = inputs.to(model.device)
# 4. infer the modeloutput_tokens = model.generate(**inputs)
# 5. decode the generated tokensdecoded_outputs = processor.batch_decode(output_tokens, skip_special_tokens=True)for output in decoded_outputs: print(output)This model was contributed by Eustache Le Bihan. The original code can be found here.
KyutaiSpeechToTextConfig
Section titled “KyutaiSpeechToTextConfig”[[autodoc]] KyutaiSpeechToTextConfig
KyutaiSpeechToTextProcessor
Section titled “KyutaiSpeechToTextProcessor”[[autodoc]] KyutaiSpeechToTextProcessor - call
KyutaiSpeechToTextFeatureExtractor
Section titled “KyutaiSpeechToTextFeatureExtractor”[[autodoc]] KyutaiSpeechToTextFeatureExtractor
KyutaiSpeechToTextForConditionalGeneration
Section titled “KyutaiSpeechToTextForConditionalGeneration”[[autodoc]] KyutaiSpeechToTextForConditionalGeneration - forward - generate
KyutaiSpeechToTextModel
Section titled “KyutaiSpeechToTextModel”[[autodoc]] KyutaiSpeechToTextModel