DPT
This model was released on 2021-03-24 and added to Hugging Face Transformers on 2022-03-28.



Overview
Section titled “Overview”The DPT model was proposed in Vision Transformers for Dense Prediction by René Ranftl, Alexey Bochkovskiy, Vladlen Koltun. DPT is a model that leverages the Vision Transformer (ViT) as backbone for dense prediction tasks like semantic segmentation and depth estimation.
The abstract from the paper is the following:
We introduce dense vision transformers, an architecture that leverages vision transformers in place of convolutional networks as a backbone for dense prediction tasks. We assemble tokens from various stages of the vision transformer into image-like representations at various resolutions and progressively combine them into full-resolution predictions using a convolutional decoder. The transformer backbone processes representations at a constant and relatively high resolution and has a global receptive field at every stage. These properties allow the dense vision transformer to provide finer-grained and more globally coherent predictions when compared to fully-convolutional networks. Our experiments show that this architecture yields substantial improvements on dense prediction tasks, especially when a large amount of training data is available. For monocular depth estimation, we observe an improvement of up to 28% in relative performance when compared to a state-of-the-art fully-convolutional network. When applied to semantic segmentation, dense vision transformers set a new state of the art on ADE20K with 49.02% mIoU. We further show that the architecture can be fine-tuned on smaller datasets such as NYUv2, KITTI, and Pascal Context where it also sets the new state of the art.
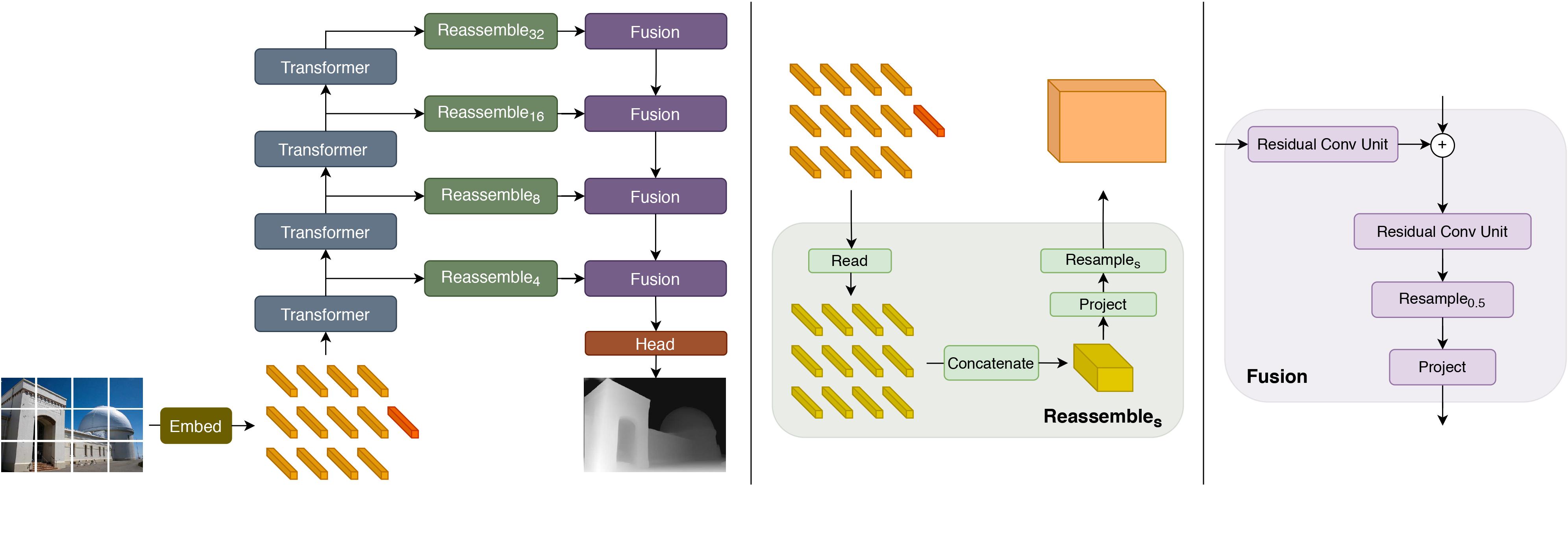
DPT architecture. Taken from the original paper.
This model was contributed by nielsr. The original code can be found here.
Usage tips
Section titled “Usage tips”DPT is compatible with the AutoBackbone class. This allows to use the DPT framework with various computer vision backbones available in the library, such as VitDetBackbone or Dinov2Backbone. One can create it as follows:
from transformers import Dinov2Config, DPTConfig, DPTForDepthEstimation
# initialize with a Transformer-based backbone such as DINOv2# in that case, we also specify `reshape_hidden_states=False` to get feature maps of shape (batch_size, num_channels, height, width)backbone_config = Dinov2Config.from_pretrained("facebook/dinov2-base", out_features=["stage1", "stage2", "stage3", "stage4"], reshape_hidden_states=False)
config = DPTConfig(backbone_config=backbone_config)model = DPTForDepthEstimation(config=config)Resources
Section titled “Resources”A list of official Hugging Face and community (indicated by 🌎) resources to help you get started with DPT.
-
Demo notebooks for
DPTForDepthEstimationcan be found here.
If you’re interested in submitting a resource to be included here, please feel free to open a Pull Request and we’ll review it! The resource should ideally demonstrate something new instead of duplicating an existing resource.
DPTConfig
Section titled “DPTConfig”[[autodoc]] DPTConfig
DPTImageProcessor
Section titled “DPTImageProcessor”[[autodoc]] DPTImageProcessor - preprocess
DPTImageProcessorFast
Section titled “DPTImageProcessorFast”[[autodoc]] DPTImageProcessorFast - preprocess - post_process_semantic_segmentation - post_process_depth_estimation
DPTModel
Section titled “DPTModel”[[autodoc]] DPTModel - forward
DPTForDepthEstimation
Section titled “DPTForDepthEstimation”[[autodoc]] DPTForDepthEstimation - forward
DPTForSemanticSegmentation
Section titled “DPTForSemanticSegmentation”[[autodoc]] DPTForSemanticSegmentation - forward